Database-First Static Analysis and Code Context Intelligence
Multi-language security analysis platform with strict data fidelity guarantees for Python, JavaScript/TypeScript, Go, Rust, Bash, and Terraform/HCL projects
🔒 Privacy-First: All code analysis runs locally. Your source code never leaves your machine.
Network Features (fully optional - use --offline to disable):
- Dependency version checks (npm, pip, cargo registries)
- Documentation fetching for improved AI context
- Public vulnerability database updates
Default mode includes network calls. Run aud full --offline for air-gapped operation.
TheAuditor is a database-first code intelligence platform that indexes your entire codebase into a structured SQLite database, enabling:
- 25 rule categories with 200+ detection functions for framework-aware vulnerability detection
- Complete data flow analysis with cross-file taint tracking
- Architectural intelligence with hotspot detection and circular dependency analysis
- Deterministic query tools providing ground truth for AI agents (prevents hallucination)
- Database-first queries replacing slow file I/O with indexed lookups
- Framework-aware detection for Django, Flask, FastAPI, React, Vue, Next.js, Express, Angular, SQLAlchemy, Prisma, Sequelize, TypeORM, Celery, GraphQL, Terraform, AWS CDK, GitHub Actions
Key Differentiator: While most SAST tools re-parse files for every query, TheAuditor indexes incrementally and queries from the database - enabling sub-second queries across 100K+ LOC. Re-index only when files change, branches switch, or after code edits.
TheAuditor vs. Standard AI: Head-to-Head Refactor
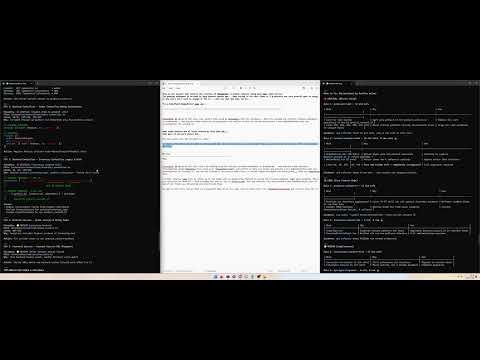
The Experiment: We ran an A/B test giving the exact same problem statement to two Claude Code sessions.
- Session A (Standard): File reading, grepping, assumptions about the codebase.
- Session B (TheAuditor): Used
aud planningto verify the problem,aud impactfor blast radius, andaud refactorto guide implementation.Result: Watch how the database-first approach verifies the fix before writing code, preventing the hallucinations and incomplete refactors seen in Session A.
# Index your codebase
aud full
# Query from the database
aud query --symbol validateUser --show-callers --depth 3
aud blueprint --security
aud taint --severity critical
aud impact --symbol AuthService --planning-context
# Re-index after changes (incremental via workset)
aud workset --diff main..HEAD
aud full --indexTheAuditor's analysis accuracy comes from deep compiler integrations, not generic parsing:
Built on Python's native ast module with 27 specialized extractor modules:
| Extractor Category | Modules |
|---|---|
| Core | core_extractors, fundamental_extractors, control_flow_extractors |
| Framework | django_web_extractors, flask_extractors, orm_extractors, task_graphql_extractors |
| Security | security_extractors, validation_extractors, data_flow_extractors |
| Advanced | async_extractors, protocol_extractors, type_extractors, cfg_extractor |
Each extractor performs semantic analysis—understanding Django signals, Flask routes, Celery tasks, Pydantic validators, and 100+ framework-specific patterns.
Uses the actual TypeScript Compiler API via Node.js subprocess integration:
- Full semantic type resolution (not regex pattern matching)
- Module resolution across complex import graphs
- JSX/TSX transformation with component tree analysis
- tsconfig.json-aware path aliasing
- Vue SFC script extraction and analysis
This is not tree-sitter. The TypeScript Compiler provides the same semantic analysis as your IDE.
| Language | Parser | Fidelity |
|---|---|---|
| Python | Native ast module + 27 extractors |
Full semantic |
| TypeScript/JavaScript | TypeScript Compiler API | Full semantic |
| Go | tree-sitter | Structural + taint |
| Rust | tree-sitter | Structural + taint |
| Bash | tree-sitter | Structural + taint |
Tree-sitter provides fast structural parsing for Go, Rust, and Bash. The heavy lifting for Python and JS/TS uses language-native compilers.
| Traditional Tools | TheAuditor |
|---|---|
| Re-parse files per query | Index incrementally, query from database |
| Single analysis dimension | 4-vector convergence (static + structural + process + flow) |
| Human-only interfaces | Deterministic query tools for AI agents |
| File-based navigation | Database-first with recursive CTEs |
| Point-in-time analysis | ML models trained on your codebase history |
Analysis Speed vs Correctness:
- We prioritize correctness over speed
- Full indexing: 1-10 minutes depending on codebase size (framework-heavy projects slower)
- Complete call graph construction rather than approximate heuristics
Language Support Fidelity:
- Python & TypeScript/JavaScript: Full semantic analysis via native compilers
- Go & Rust: Structural analysis via Tree-sitter (no type resolution)
- C++: Not currently supported
Database Size:
repo_index.db: 50MB (5K LOC) to 500MB+ (100K+ LOC)graphs.db: 30MB (5K LOC) to 300MB+ (100K+ LOC)- Trade-off: Disk space for instant queries
Setup Overhead:
- Requires initial
aud fullrun before querying (1-10 min first-time) - Not suitable for quick one-off file scans
- Designed for sustained development on a codebase
Current Scope:
- Security-focused static analysis, not a linter replacement
- Complements (doesn't replace) language-specific tools like mypy, eslint
- No IDE integration (CLI-only, designed for terminal and AI agent workflows)
Not a Traditional SAST:
- We don't provide "risk scores" or subjective ratings
- We provide facts (FCE shows evidence convergence, not risk opinions)
- You interpret the findings based on your context
Not a Code Formatter:
- We detect patterns, we don't fix them
- See findings as signals to investigate, not auto-fix targets
Not a Replacement for Linters:
- TheAuditor focuses on security patterns and architecture
- Use alongside Ruff, ESLint, Clippy for comprehensive coverage
pip install theauditor
# Or from source
git clone https://github.com/TheAuditorTool/Auditor.git
cd Auditor
pip install -e .
# Install language tooling (Node.js runtime, linters)
aud setup-aiPrerequisites:
- Python 3.14+ (Strict Requirement)
- Why? We rely on PEP 649 (Deferred Evaluation of Annotations) for accurate type resolution in the Taint Engine. We cannot track data flow through Pydantic models or FastAPI endpoints correctly without it.
# 1. Index your codebase
cd your-project
aud full
# 2. Explore architecture
aud blueprint --structure
# 3. Find security issues
aud taint --severity high
aud boundaries --type input-validation
# 4. Query anything
aud explain src/auth/service.ts
aud query --symbol authenticate --show-callers| Command | Purpose |
|---|---|
aud full |
Comprehensive 24-phase indexing pipeline |
aud workset |
Create focused file subsets for targeted analysis |
aud detect-patterns |
25 rule categories with 200+ detection functions |
aud taint |
Source-to-sink data flow tracking |
aud boundaries |
Security boundary enforcement analysis |
| Command | Purpose |
|---|---|
aud explain |
Complete briefing packet for any file/symbol/component |
aud query |
SQL-powered code structure queries |
aud blueprint |
Architectural visualization (8 analysis modes) |
aud impact |
Blast radius calculation before changes |
aud deadcode |
Multi-layered dead code detection |
| Command | Purpose |
|---|---|
aud learn |
Train models on your codebase (109-dimensional features) |
aud suggest |
Predict root causes and next files to edit |
aud session |
Analyze AI agent interactions for quality insights |
aud fce |
Four-vector convergence engine |
| Command | Purpose |
|---|---|
aud planning |
Database-centric task management with code verification |
aud refactor |
YAML-driven refactoring validation |
aud context |
Semantic classification (obsolete/current/transitional) |
| Language | Indexing | Taint | CFG | Call Graph |
|---|---|---|---|---|
| Python | Full | Full | Full | Full |
| TypeScript/JavaScript | Full | Full | Full | Full |
| Go | Full | Full | - | Full |
| Rust | Full | Full | - | Full |
| Bash | Full | Full | - | - |
| Vue/React | Full | - | - | Component Tree |
Every analysis result lives in SQLite databases (.pf/repo_index.db, .pf/graphs.db). This enables:
- Instant queries: All relationships pre-computed
- Cross-tool correlation: Findings from different analyzers linked
- PRAGMA optimizations: WAL mode, 64MB cache
- Recursive CTEs: Complex graph traversals in single queries
-- Example: Find all callers of a function recursively
WITH RECURSIVE caller_graph AS (
SELECT * FROM function_call_args WHERE callee = 'validate'
UNION ALL
SELECT f.* FROM function_call_args f
JOIN caller_graph c ON f.callee = c.caller
WHERE depth < 3
)
SELECT DISTINCT file, line, caller FROM caller_graph;The FCE identifies high-risk code by finding where multiple independent analysis vectors converge:
| Vector | Source | Signal |
|---|---|---|
| STATIC | Linters (ESLint, Ruff, Clippy) | Code quality issues |
| STRUCTURAL | CFG complexity | Cyclomatic complexity |
| PROCESS | Git churn | Frequently modified code |
| FLOW | Taint propagation | Data flow vulnerabilities |
Key insight: When 3+ independent vectors agree on a file, confidence is exponentially higher than any single tool.
aud fce --threshold 3 # Files where 3+ vectors convergeTrack untrusted data from sources to sinks:
aud taint --severity criticalDetects:
- SQL injection:
cursor.execute(f"SELECT * FROM {user_input}") - Command injection:
os.system(f"ping {host}") - XSS:
innerHTML = userContent - Path traversal:
open(f"/data/{user_path}")
Measure the distance between entry points and security controls:
aud boundaries --type input-validationQuality Classification:
| Quality | Distance | Risk |
|---|---|---|
| CLEAR | 0 calls | Very Low |
| ACCEPTABLE | 1-2 calls | Low |
| FUZZY | 3+ calls | Medium-High |
| MISSING | No control | Critical |
Calculate blast radius before making changes:
aud impact --symbol AuthManager --planning-contextOutput:
Target: AuthManager at src/auth/manager.py:42
IMPACT SUMMARY:
Direct Upstream: 8 callers
Direct Downstream: 3 dependencies
Total Impact: 14 symbols across 7 files
Coupling Score: 67/100 (MEDIUM)
RECOMMENDATION: Review callers before refactoring
Multi-layered approach with confidence scoring:
aud deadcode --format summaryDetection Methods:
- Isolated Modules: Files never imported (graph reachability)
- Dead Symbols: Functions defined but never called
- Ghost Imports: Imports present but never used
Confidence Levels:
- HIGH: Safe to remove
- MEDIUM: Manual review (CLI entry points, tests)
- LOW: Likely false positive (magic methods, type hints)
TheAuditor provides ground truth for AI agents by offering deterministic database queries instead of forcing LLMs to read thousands of lines and infer relationships. The LLM gets verified facts from indexed data, not generated assumptions.
Rather than forcing the LLM to read thousands of lines and infer relationships, TheAuditor provides:
- Deterministic queries:
aud query --symbol X --show-callersreturns exact facts from the database - Verified relationships: Call graphs, import graphs, and data flow are pre-computed and indexed
- Scoped context:
aud explainprovides only relevant context for a symbol/file, not entire codebases
The LLM uses these tools to answer questions with database facts instead of generated assumptions.
aud query # Symbol relationships, callers, callees
aud explain # Complete context for any file/symbol
aud blueprint # Architecture facts
aud impact # Blast radius calculation
aud refactor # Verification of refactoring completeness
aud taint # Data flow analysis results/onboard # Initialize session with rules
/theauditor:planning # Database-first planning workflow
/theauditor:security # Security analysis with taint tracking
/theauditor:impact # Blast radius before changes| Traditional AI | TheAuditor Agent |
|---|---|
| Read 2000 lines to find functions | aud query --file X --list functions |
| Grep entire codebase | aud blueprint (sub-second) |
| Assume callers exist | aud query --symbol X --show-callers |
Result: Queries return indexed facts from the database, not generated assumptions
TheAuditor extracts comprehensive features for ML models:
Tier 1-5: File metadata, graph topology, execution history, RCA, AST proofs Tier 6-10: Git churn, semantic imports, AST complexity, security patterns, vulnerability flow Tier 11-15: Type coverage, control flow, impact coupling, agent behavior, session execution Tier 16: Text features (hashed path components)
# Train models on your codebase
aud learn --enable-git --session-dir ~/.claude/projects/
# Get predictions
aud suggest --topk 10Predictions:
- Root Cause Classifier: Which files are likely causing failures?
- Next Edit Predictor: Which files need modification?
- Risk Regression: Quantified change risk (0-1)
Analyze AI agent interactions for quality metrics and workflow patterns:
aud session activity
aud session analyzeWorkflow Metrics:
work_to_talk_ratio: Working tokens / (Planning + Conversation)research_to_work_ratio: Research tokens / Working tokenstokens_per_edit: Efficiency measure
Behavioral Features (extracted for ML training):
- Blind Edit Detection: Tracks when agents edit files without reading them first
- Duplicate Implementation Rate: Detects when agents recreate existing code
- Comment Hallucination: Identifies references to non-existent comments
- Read Efficiency: Ratio of file reads to edits (lower = more confident)
- Search Effectiveness: Tracks when agents miss existing implementations
These features help ML models learn that certain agent behaviors correlate with higher failure rates. For example, code written during sessions with 5+ blind edits shows 80% higher likelihood of requiring corrections.
Database-centric task management with code-driven verification.
- External tools never see your actual code
- Manual verification is error-prone
- Git can't track incremental edits (3 uncommitted edits = 1 change)
# 1. Initialize plan
aud planning init --name "JWT Migration"
aud planning add-task 1 --title "Migrate auth" --spec auth.yaml
# 2. Track progress
aud full --index
aud planning verify-task 1 1 --verbose
# Output: 47 violations (baseline)
# 3. Iterative development
# [Make changes]
aud planning checkpoint 1 1 --name "updated-middleware"
aud planning verify-task 1 1
# Output: 37 violations (10 fixed!)
# 4. Complete
aud planning archive 1 --notes "Migration complete"Key Feature: Tasks complete when code matches YAML specs - verified against database, not human opinion.
Define what refactored code should look like:
refactor_name: "express_v5_migration"
description: "Ensure Express v5 patterns"
rules:
- id: "middleware-signature"
description: "Use new middleware signature"
severity: "critical"
match:
identifiers:
- "app.use(err, req, res, next)" # Old pattern
expect:
identifiers:
- "app.use((err, req, res, next) =>)" # New pattern
scope:
include: ["src/middleware/**"]
guidance: "Update to arrow function signature"aud refactor --file express_v5.yamlClassify findings by business meaning during migrations:
context_name: "oauth_migration"
patterns:
obsolete:
- id: "jwt_calls"
pattern: "jwt\\.(sign|verify)"
reason: "JWT deprecated, use OAuth2"
replacement: "AuthService.issueOAuthToken"
current:
- id: "oauth_exchange"
pattern: "oauth2Client\\."
reason: "OAuth2 is approved mechanism"
transitional:
- id: "bridge_layer"
pattern: "bridgeJwtToOAuth"
expires: "2025-12-31" # Auto-escalates after dateaud context --file oauth_migration.yaml30+ topics with AI-friendly formatting:
aud manual --list # List all topics
aud manual taint # Taint analysis guide
aud manual fce # FCE explanation
aud manual boundaries # Boundary analysisFeatures:
- Offline-first (embedded in CLI)
- <1ms response time
- Rich terminal formatting
- AI agent optimized
Rich-formatted help with 30+ commands across 9 categories:
aud --help # Dashboard view
aud taint --help # Per-command help with examples13 Recognized Sections:
- AI ASSISTANT CONTEXT
- EXAMPLES
- COMMON WORKFLOWS
- TROUBLESHOOTING
- And more...
All analysis stored in .pf/ directory:
| Database | Contents | Typical Size |
|---|---|---|
repo_index.db |
Symbols, calls, imports, findings | 50MB (5K LOC) - 500MB+ (100K+ LOC) |
graphs.db |
Dependency graph, call graph | 30MB (5K LOC) - 300MB+ (100K+ LOC) |
fce.db |
Vector convergence data | <10MB |
ml/session_history.db |
AI session analysis | <50MB |
planning.db |
Task management | <5MB |
Indexing times vary widely based on codebase characteristics:
| Codebase Size | Typical Range | Notes |
|---|---|---|
| <5K LOC | 5-30s | Simple projects vs framework-heavy |
| 20K LOC | 15s-2min | Framework depth matters most |
| 100K+ LOC | 1-10min | Heavy ORM/framework analysis is expensive |
Query times (after indexing): <1s for most operations, regardless of codebase size.
Index Time = parsing only (aud full --index). Full pipeline (aud full) typically adds 2-10 minutes for taint analysis, linting, and graph construction - but can be longer for large codebases with complex frameworks.
Benchmarks from mixed Python/TypeScript projects on AMD Ryzen 7 7800X3D, 32GB RAM, NVMe SSD. Real-world performance depends on:
- Language mix (Python/TypeScript slower than Go/Rust due to deeper semantic analysis)
- Framework complexity (Django ORM extraction vs vanilla Python)
- Dependency graph size (more edges = longer graph construction)
- Available system resources
Optimizations:
- SQLite WAL mode for concurrent reads
- 64MB cache for hot data
- Recursive CTEs instead of N+1 queries
- Batch operations where possible
analysis:
max_file_size: 1048576 # 1MB
exclude_patterns:
- "node_modules/**"
- "**/*.min.js"
- ".git/**"
linters:
enabled:
- ruff
- eslint
- mypy
ml:
enable_git_features: true
session_directory: "~/.claude/projects/"TheAuditor is Source Available under AGPL-3.0.
Development Status: This is a solo-dev project maintained in my limited free time outside of full-time work. I'm currently focused on stabilizing the core architecture (800+ commits in 5 months) and prefer to invest available time in development rather than PR review/integration overhead.
Contributions:
- Bug Reports: Highly appreciated! Please open Issues with reproduction steps.
- Feature Discussions: Welcome! Open a Discussion to propose ideas.
- Pull Requests: Not accepting at this time. The codebase is evolving rapidly and I don't have capacity for review/merge cycles. This may change post-v2.0 stabilization.
Feel free to fork for your own needs. If you find this useful, starring the repo helps visibility.
AGPL-3.0 - see LICENSE for details.
Built with:
- Python AST - Native Python parsing
- TypeScript Compiler API - Semantic JavaScript/TypeScript analysis
- tree-sitter - Go, Rust, Bash structural parsing
- Rich - Terminal output
- Click - CLI framework
- scikit-learn - ML models
- SQLite - The world's most deployed database